With Ariel Young
The impact of the coronavirus is steadily growing to become the most devastating disaster in a half century, in terms of the cost to human life as well as the economic and social impact it has had around the world. In just nine months since the outbreak began in January 2020, at least one million lives have been claimed globally. Attempting to learn more about the consequences of the pandemic a number of recent publications have made the claim that the coronavirus and its impacts represent a ‘natural experiment.’ In the world of research methods, this would mean that the coronavirus pandemic produces a set of conditions which resemble a truly randomized lab experiment. This would allow an investigator to identify causal effects – as opposed to mere correlations – virtually free of bias. This is a fascinating prospect to come out of an unfortunate situation, but we would like to issue a dose of caution that much of the optimism about being able to use the pandemic in such a way is premature and that experimental conditions will only be met under very specific circumstances. Instead of rushing to publish headline grabbing claims, we argue for the need to take a step back and evaluate these conditions very carefully.
The term natural experiment takes its cue from the scientific gold standard of a randomized experiment, but differs in that the researcher does not actually manipulate the assignment of subjects to either a treatment or control group. Instead, this assignment is the consequence of some process or event out in the real world. In order to highlight the key features and assumptions of what is needed for such a process or event to qualify as a natural experiment, we will briefly consider a typical case of a randomized experiment, namely a clinical trial of an antiviral drug. Following this, we will outline why we think the coronavirus outbreak and the following policy responses rarely meet the assumptions necessary to qualify as a natural experiment. Finally, we will provide some brief examples of when we do think that there is potential to use this research strategy in relation to the pandemic.
First, imagine a simple clinical study where a group of scientists are trying to assess if an experimental cancer drug (treatment) reduces mortality in cancer patients. They would begin by assigning the patients at random to either receive the treatment or to receive a placebo (i.e., an injection filled with dextrose or a sugar-pill, to the patient visually indistinguishable from the experimental drug). This random assignment ensures that on average, the treatment and control groups will be statistically equivalent before the treatment is given – either group will not be systematically older, have more severe cases or have an a priori better outlook for recovery. When later comparing the outcomes of the two groups, any statistically important differences measured between the groups (suppose the people who got the treatment survived 30% longer on average) would have to be a causal consequence of having received the treatment. In this way, we can feel assured that the treatment really worked.
This ideal can break down in many different ways. Consider for example if a sentimental experimenter feeling sorry for the younger patients chose to skimp the random protocol and disproportionately assign them to the treatment group. This might appear to make ethical sense – younger patients have a lot more life years to gain, for example. However, if the results now show that mortality was reduced by 30% on-average in the treatment group, this could just as well be explained by a situation where even absent the drug, the younger patients had better chances to recover anyway. Or suppose that the patients in the control group manage to figure out that they are not actually getting the active treatment (their pills don’t smell the same!) and consequently procure the drug themselves from other sources. The researchers might now find that the patients in the treatment and control groups show just the same mortality, and conclude that the treatment is useless – even if it was effective in reality. We just happened to compare people who got it within the protocol with people who managed to get it on their own.
Translating the experimental ideal to a real-world observational[1] setting, the investigator must be able to argue convincingly that their study possesses a few key features to meet the standard of a natural experiment:
1. Assignment to treatment and control groups are “as-good-as” random. An investigator does not actually manipulate the assignment of a set of individuals to the control or treatment group, and instead only observes outcomes after the fact. Investigators must therefore argue that the assignment process is random with respect to all factors that could conceivably affect the outcome they are interested in (e.g., age in the case of the drug trial). If they are correct, the groups would be similar (statistically equivalent) on both observable and unobservable factors – with the exception of the treatment – and we can therefore be sure that these other factors didn’t cause the difference in outcomes. It is important to note that the term “natural” in the context of a natural experiment therefore doesn’t necessarily have to mean an event caused by nature proper, but just that it is an event out of the researcher’s control.
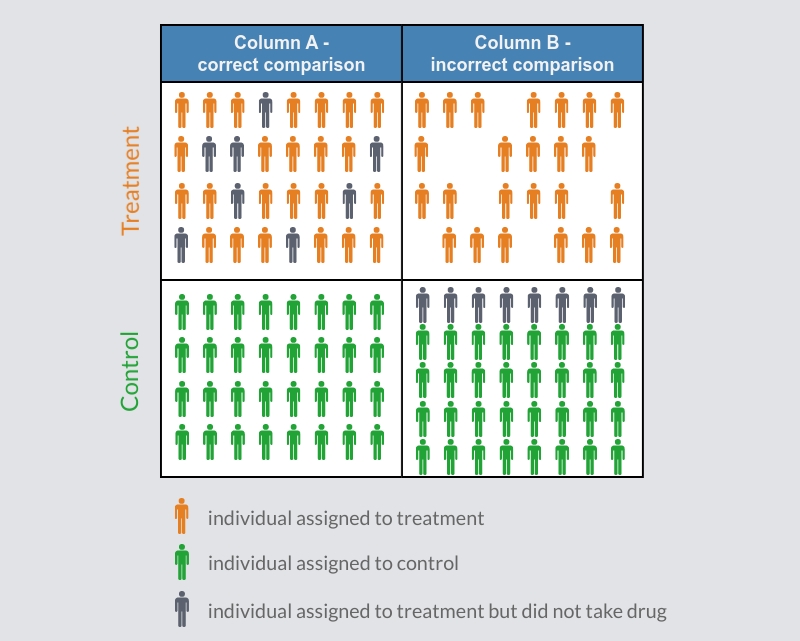
2. The investigator must be able to reliably identify the treatment and control groups. Since the groups are defined by the researcher after the natural intervention takes place rather than before, it is possible to make errors that end up sorting them in a way that makes them not statistically similar. To describe the misidentification of control and treatment groups, consider the hypothetical clinical example as illustrated in Figure 1 below. Assume that the random assignment of patients unfolds exactly as planned (column A), but add a common spoiler: some of the patients in the treatment group failed to show up to take their medication (grey character). If we now simply compare whether a patient took the medication or not (column B), rather than correctly comparing whether they were assigned to the treatment group or not, we would be comparing non-equivalent groups (column B) – that is, those individuals from the treatment group that failed to take the drug (grey character) would be incorrectly assigned to the control group. Thus, we’re comparing two groups that were not on average equally motivated to take the drug. As a result, we would not be able to know if it was really the treatment that made any difference, or in this case, some underlying factor common to those that had the motivation to take the medication (for example, if people with worse symptoms were more inclined to comply with the protocol). Again, when an investigator relies on the use of observational data, and makes the claim that their design is a natural experiment, it is more common than not that they incorrectly sort subjects into the control and treatment groups, leading to biased results.
Figure 1
3. Treated and untreated units must remain statistically independent. This can appear somewhat technical, but is a simple matter of being sure that any treatment effect hasn’t “spilled over” to the untreated group. To describe spillover let’s imagine a hypothetical field-experiment. Suppose local governments want to find out if mask mandates reduce the spread of disease. They study two neighboring communities, and assign community A to the treatment group (mask mandates) and community B to the control (no mask mandates). Let’s assume that the mask mandate (treatment) really does reduce transmission and that neighboring communities’ A and B are equivalent in other respects. To make an accurate comparison, the researchers must be sure that the people in the un-treated community (B) aren’t simply observing the behavior of the people in the neighboring treated community (A) and emulating them – in effect making them “treated” as well. If such spillover occurs, the differences in transmission between the two communities would decrease and we would incorrectly infer that the mandate had no effect, when in fact it did.
With these important caveats in mind, we will now go on to examine some of the proposed ways in which the pandemic and policy responses have been argued to represent a natural experiment.
First off, at the individual level, it is clear that virus transmission does not occur at random. For example, it appears that the virus spreads much more easily among people in more disadvantaged socioeconomic groups (probably due to a mix of living conditions and workplace exposure) (e.g., Abedi et al 2020; Shadmi et al 2020). This means that any research strategies premised on the argument that the infected vs. uninfected status represents a naturally randomized treatment are bound to be heavily biased and do not qualify as natural experiments.
Next, the pandemic has led to policy responses that recommend or mandate various degrees of physical distancing, whether it be in the form of more relaxed recommendations for individuals to reduce their activities in public (e.g. Sweden) or highly restrictive shelter-at-home orders (e.g. Italy). Comparisons between these types of policy interventions have been claimed by several sources to be a type of natural experiment. For example, news articles have construed the different start-dates and degree of social distancing orders between neighboring U.S. States as natural experiments that can explain the effectiveness of reducing the coronavirus infection or mortality rate. In one case, researchers used the different lock-down orders between the bordering countries of Sweden and Denmark to explain the differences in reduced economic spending. The term natural experiment is used numerous times to describe these, and other, comparisons. However, with the previous discussion in mind, it should be clear that they do not constitute natural experiments, and therefore more than likely provide poor evidence of a causal impact. Let’s see why.
Authorities at the national, state, or county level do not use a truly random assignment process (e.g., flip of a coin), or something resembling randomization, to determine if a more relaxed or more restrictive social distancing order is implemented. Rather, in the case of the United States it is apparent that the initial policy response to the coronavirus[2] varied in a manner that was highly correlated with whether a Republican or Democratic governor was in office (Gershman 2020; National Governors Association 2020). What is most significant about the differences in policy response among Republican and Democratic leadership is that it is correlated with other factors that are known to affect infection rate. This will result in a situation where non-equivalent groups are compared to assess the effectiveness of social distancing orders on infection-rates.[3]
To illustrate this point we use Figure 2. On the vertical axis, we see restriction intensity: less or relaxed restrictions on the bottom half and more or stricter restrictions on the top-half. On the horizontal axis, we label two categories, “Local Government’s Party” (Republican or Democratic) and “Rural or Urban”. Simulating (in a simplistic manner[4]) what we know about the average partisan policy response to the coronavirus we see that states run by Republican (red) leaders populate a larger share of the bottom box, and Democratic (blue) states the top box. We label the bottom boxes as the control and the top box as the treatment. As mentioned earlier party popularity is correlated with various factors known to affect infection rate, in this case a rural or urban setting. Evidence shows that Republicans on-average enjoy greater support in rural areas, whereas Democrats have stronger support in urban areas (Mckee 2008; Scala and Johnson 2017)[5]. As Figure 2 shows, rural areas are overrepresented in the control group under the Rural or Urban category. This results in a sorting that fails to produce statistically equivalent treatment and control groups, a critical criterion of a natural experiment.
Figure 2

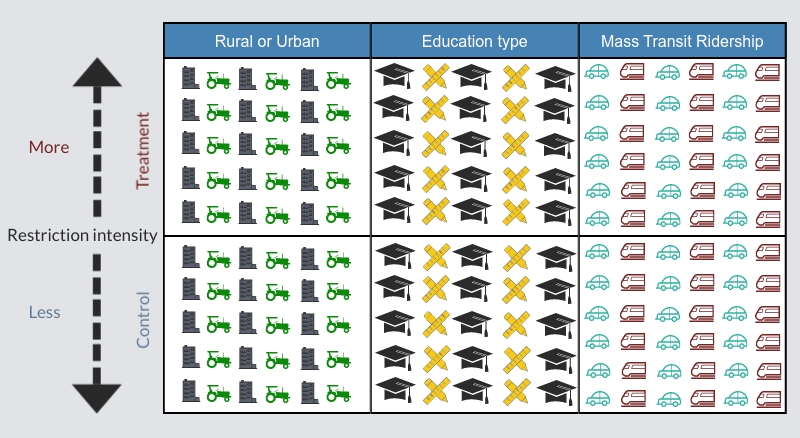
In the case of a rural versus urban setting we know that frequent physical contact between humans is naturally more prevalent in urban areas, as opposed to rural areas. That is, if you reside in an urban area, on average you are more likely to come into close-contact with other individuals (e.g., strangers in the bus/metro or co-workers indoors). These types of factors are typically key to accelerating the spread of any transmissible pathogen, including Covid-19. With a greater natural distance between individuals in rural areas there is consequently less opportunity for the virus to spread. By comparing (for example) infection rates among areas that imposed restrictions to areas that didn’t, we would be comparing more urban areas to more rural areas and consequently areas with more and less naturally occurring rates of transmission. Instead, to accurately measure the effect of a strict social distancing order (treatment) one would need to equally sort all (known and unknown) factors that impact the rate of spread of the virus between treatment and control groups[6]. Figure 3 illustrates equal sorting into treatment and control groups of factors[7] known to affect covid infection rates. This is opposite to what we see in the case of the pattern of social distancing orders observed across the U.S.
Figure 3
The problem of spillover effects mentioned above poses a similar difficulty for such comparisons. As some locations issue firm stay-at-home orders, a certain proportion of people in neighboring locations may take the cue and do the same even in the absence of a formal constraint. This is an example of spillover which results in undermining the independence assumption, and will consequently result in underestimating the effect of distancing measures.
So – in what sense do we think that the natural experiment research strategy actually does make sense to investigate aspects of the coronavirus pandemic? There are a few notable examples out there that are worth bringing to light. First, there is a set of phenomena that can cause as-good-as random variation in the exposure to the virus. One such phenomenon is weather, which under some circumstances can plausibly be seen as random with respect to other factors influencing the spread. For example, in a study (posted as a preprint) by sociologists Patrick Sharkey and George Wood (2020), variation in weather is used to infer changes in how much people socialize (over the short-term), which in turn is shown to affect subsequent viral transmission. While socialization patterns by themselves are not random, changes in these patterns caused by bad weather most likely are, at least on this time scale (in the long run, more permanent changes to weather patterns may of course cause certain types of people to move etc.). This therefore constitutes a good example of how it could be possible to leverage natural random variation to investigate causal questions about the pandemic.
We may also observe as-good-as random events other than weather, like major sporting events in the crucial starting days of disease introduction. Consider that some processes of deciding where a game should be held are actually decided by lottery, or perhaps even the sort of randomness introduced by the touring schedule of some major artist. The types of processes that can introduce random variation, in this sense, can be far removed from actual viral transmission or direct policy response. A search for such processes will prove more fruitful if conducted with a broad searchlight and an open mind – but of course with great attention to detail.
The challenges of measuring cause-and-effect that we have discussed here equally applies to all outcomes of the pandemic, including the relationship between school shut-downs and standardized testing results, stay-at-home orders and crime rate, or shelter-in-place orders and economic decline. For additional information and details on natural experiments we recommend you consult the following publications: Dunning (2008), Dunning (2012), Rosenzweig and Wolpin (2000), Sekhon and Titiunik (2012).
In closing, research being conducted on the effects of the covid-19 pandemic is going to provide important contributions to the scientific knowledge about the current virus, about future pandemics and about the best way to respond to the challenges that they pose. This is true regardless of whether that research is based on natural experiments or not. However, when making causal claims about the real world, with real-world data, and in particular when inferring that a particular real-world event presents us with experimental conditions, we have to be careful about evaluating whether the rigorous methodological demands we should expect from a natural experiment are actually met. In most cases, they will not be, and therefore the strong causal conclusions that these research designs can provide should be withheld. We argue that this is not merely a question of semantics, but that it is worth reserving the experimental nomenclature for situations where it is actually applicable.
References:
Abedi, Vida, Oluwaseyi Olulana, Venkatesh Avula, Durgesh Chaudhary, Ayesha Khan, Shima Shahjouei, Jiang Li, and Ramin Zand. 2020. “Racial, Economic, and Health Inequality and COVID-19 Infection in the United States.” Journal of Racial and Ethnic Health Disparities. doi: 10.1007/s40615-020-00833-4.
Dunning, Thad. 2008. “Improving Causal Inference: Strengths and Limitations of Natural Experiments.” Political Research Quarterly 61(2):282–93. doi:10.1177/1065912907306470.
Dunning, Thad. 2012. Natural Experiments in the Social Sciences. Cambridge University Press.
Gershman, Jacob. 2020. “A Guide to State Coronavirus Reopenings and Lockdowns.” Wall Street Journal, May 20.
McKee, Seth C. 2008. “Rural Voters and the Polarization of American Presidential Elections.” PS: Political Science & Politics 41(01):101–8. doi: 10.1017/S1049096508080165.
National Governors Association 2020. “Governors Roster 2020: Governors’ Political Affiliations & Terms of Office.” Retrieved September 21, 2020 (https://www.nga.org/wp-content/uploads/2019/07/Governors-Roster.pdf).
Rosenzweig, Mark R., and Kenneth I. Wolpin. 2000. “Natural ‘Natural Experiments’ in Economics.” Journal of Economic Literature 38(4):827–74.
Scala, Dante J., and Kenneth M. Johnson. 2017. “Political Polarization along the Rural-Urban Continuum? The Geography of the Presidential Vote, 2000–2016.” The ANNALS of the American Academy of Political and Social Science 672(1):162–84. doi: 10.1177/0002716217712696.
Sekhon, Jasjeet S., and Rocío Titiunik. 2012. “When Natural Experiments Are Neither Natural nor Experiments.” American Political Science Review 106(1):35–57. doi:10.1017/S0003055411000542.
Shadmi, Efrat, Yingyao Chen, Inês Dourado, Inbal Faran-Perach, John Furler, Peter Hangoma, Piya Hanvoravongchai, Claudia Obando, Varduhi Petrosyan, Krishna D. Rao, Ana Lorena Ruano, Leiyu Shi, Luis Eugenio de Souza, Sivan Spitzer-Shohat, Elizabeth Sturgiss, Rapeepong Suphanchaimat, Manuela Villar Uribe, and Sara Willems. 2020. “Health Equity and COVID-19: Global Perspectives.” International Journal for Equity in Health 19(1):104. doi: 10.1186/s12939-020-01218-z.
Sharkey, P. and G. Wood. 2020. “The Causal Effect of Social Distancing on the Spread of Sars-cov-2”. Retrieved (osf.io/preprints/socarxiv/hzj7a).
Wooldridge, Jeffrey M. 2016. Introductory Econometrics: A Modern Approach. Sixth edition. Boston, MA: Cengage Learning.
[1] “Nonexperimental data are sometimes called observational data, or retrospective data, to emphasize the fact that the researcher is a passive collector of the data” (Wooldridge 2016: 2).
[2] Before May 21st, 2020
[3] One could also assess the effect of social distancing orders on economic decline, educational outcomes, domestic violence, etc.
[4] This example and the figures are a simplification of the real-world. They are not meant to depict actual demographic statistics but to simply illustrate the challenges of drawing inferences from observational data.
[5] Other factors include population density, share of multigenerational households, share of mass transit ridership (buses/metro), average education level of the population, average age of the local population, etc.
[6] One could attempt to statistically control for other factors known to affect coronavirus infection rates. However, this approach is unlikely to eliminate all bias. There are many unknowns about how the virus spreads, making it implausible to control for all forms of observed and unobserved bias. Therefore, a natural experiment provides a much more effective approach for measuring the causal effect.
[7] A rural or urban setting, a population with either a high-school or college degree (education), and personal vehicle or mass transit ridership.

