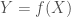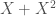When we’re trying to statistically work out whether a correlation, effect or treatment outcome is particularly strong (or even whether the sign varies) among certain types of units or is dependent on some other variable, we typically use interaction models – and more specifically, multiplicative interaction terms in some linear regression framework. Interaction models, like any model, provide a rich variety of possible mistakes and pitfalls. In this post I have gathered a few of the mistakes that we should avoid, of varying degrees of sophistication. Throughout, I assume that the reader is familiar with the basics of linear regression analysis.
I’ll probably be adding more to the list – feel free to holler if you think there is anything that should be on!
1. Failing to include constitutive terms
A mistake that perhaps isn’t very common nowadays is to neglect to include the constitutive terms. That is, to specify a model like the following:

rather than the correctly specified

The intuitive argument often goes along the lines of “well I’m not interested in the effects of X or Z by themselves, but only in their interaction, so therefore I should leave them out.”
This, however, is a misspecification that produces meaningless results. Why? Consider as an example a case where the true 


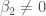
2. Interpreting coefficients for constitutive terms as unconditional effects
A related error when interpreting coefficients from the correctly specified 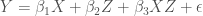

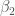
This is conceptually nonsensical since the point of including an interaction in the first place is to let the effect of X vary. We can also have a look at the marginal effect:

That is, 

3. Using linearly specified controls
Let’s say we suspect that the interaction effect between X and Z is in fact driven by some other variable, 
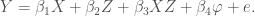
Done? Unfortunately not: we have controlled for the linear effect of
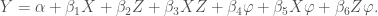
There, that’s better!
4. Missing non-linear main effects: correlated IV’s
This one I’ve described before in much more detail in this post. To recap briefly: if X and Z are also correlated with each other, any unspecified non-linearity in the main effects (

5. Missing non-linear main effects: range of X dependent on Z
A special case of nr 4 above is when the main effect of X is truly non-linear, but the range of X is dependent on Z. Suppose, for example, that the functional form of