TL;DR: within-family models have been argued to suffer from a magnification of attenuation bias compared to between-family models. However, this is only true under the assumption of uncorrelated measurement errors. This is not very realistic, and under reasonable conditions it is possible that within-family models actually suffer from less attenuation bias than between-family models.
Family fixed-effects models – and in particular so-called discordant twin models which use within-family differences among identical twins – have gained a fair amount of popularity in attempting to get closer to causal estimates of effects of interest, free from a range of possible confounding factors related to childhood environment, upbringing and genetics. In my own field of political behavior, results from these types of studies typically show that effects are much smaller than what even conservative conventional multiple regression estimates adjusted for a wide range of confounders tend to show. The conclusion drawn from this pattern (by me and others) is that a lot of published observational research probably suffers from a fairly large amount of bias, despite the best efforts of researchers to apply stringent controls.
A criticism that is sometimes leveled against this approach (e.g. Frisell et al. 2012) is that most independent variables are measured with some error, and that attenuation bias is magnified in fixed-effects models in direct proportion to the intra-class correlation in the exposure. Therefore, it is argued, we should observe smaller effect sizes in family fixed-effects models even in the absence of any familial confounding. Using e.g. a discordant twin model would then bias the effect estimate toward zero more than a between-family model would, and the overall conclusion that previous studies were positively biased may be entirely an artefact of this magnification of attenuation bias.
It is fairly straight forward to show this analytically. Suppose we have a sample of sibling data and standardized independent variables 

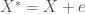
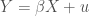
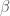
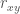
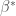
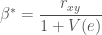
The larger the noise component 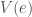
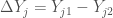


That is, 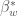
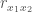
That summarizes the previous argument against comparing between- and within-family models. So far so good (or bad for family fixed effect models, as it would seem). Except that this is only true when the measurement error is completely uncorrelated within families. Let’s relax this assumption, shall we? If we instead allow not just 
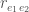
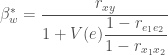
(The curious reader may find it a stimulating exercise to derive this expression). If the measurement error in
In most cases, I think we should expect a fair amount of sibling correlation (and especially twin correlation) in the measurement error, both due to mechanical and more substantive forces. Mechanical forces would be things like cohort differences in the definitions of a variable. Consider, for example, a register based measurement of years of education, or employment status. If the definition changes, it is going to affect everyone in the same cohort equally, and the resulting measurement error is going to be completely absorbed when only comparing individuals born in the same cohort (i.e. twins, by definition). Similarly, using different survey instruments in different waves of a longitudinal study will usually have the same effect.
Substantive forces are arguably going to be even more important in cases where family factors provide a sort of “reference point” for an individual’s expectations about the distribution of a given construct. Consider a survey instrument for measuring e.g. trait extraversion. The extent to which someone considers themselves to be more or less extraverted is most likely going to be affected by how they perceive themselves relative to a reference point partially provided by their rearing environment. For siblings (or dizygotic twins), who may be differentially genetically inclined to be extraverted, but still grow up in the same environment, the perception of what would be considered more or less extraverted than average could conceivably be near perfectly correlated. It is then, in fact, not unreasonable to expect that in these cases, the within-family correlation in the measurement error may even be larger than in the actual trait, resulting in within-family effect estimates that are less prone to attenuation bias than their between-family counterparts.

